你好,我是郑工长。
又发现一个OpenClaw使用中的问题:私聊可以分析图片,但群聊和 WebChat 中机器人说"图片没有成功传递给我"
本文档详细说明如何配置 OpenClaw 的多模态模型,使其在群聊、私聊和WebChat中都能正确识别和分析图片。
📋 问题现象
✅ 正常情况
- 私聊发送图片 + "分析这张图片" → 机器人可以分析图片内容
❌ 问题情况
- 群聊发送图片并@机器人 → 机器人回复:"图片好像没有成功传递给我"
- WebChat 发送图片 → 机器人无法识别图片
🔍 日志分析
群聊图片消息日志:
feishu: post message contains 1 embedded image(s)
feishu: downloaded embedded image img_v3_02vi_..., saved to /Users/xxx/.openclaw/media/inbound/xxx.jpg
feishu[default]: dispatching to agent
关键发现:
- ✅ 图片已成功下载并保存到本地
- ✅ 媒体数据已生成 (mediaPayload)
- ❌ 但模型说"看不到图片"
🐛 问题根源
核心原因
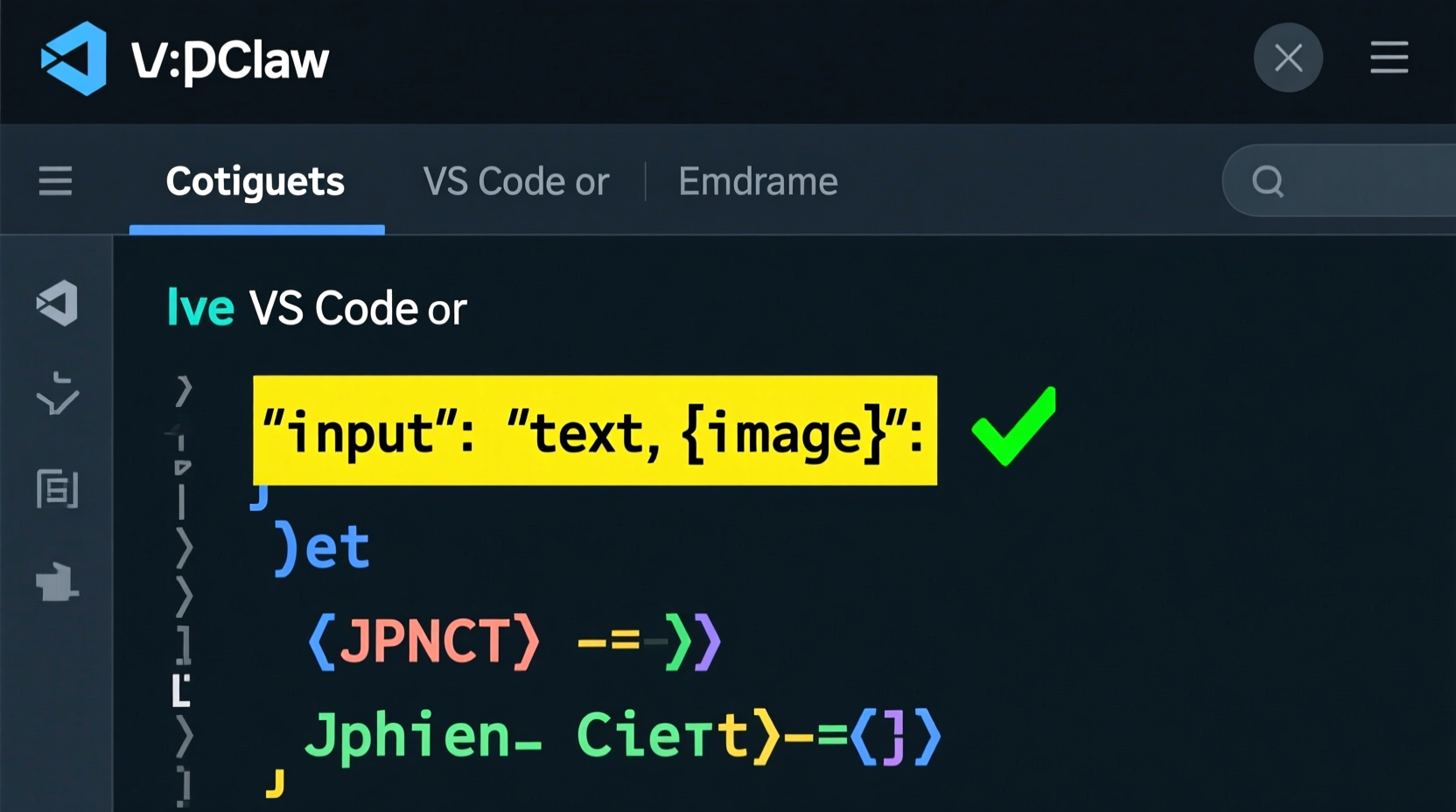
模型配置中缺少 "image" 输入类型支持。
查看 ~/.openclaw/openclaw.json 中的模型配置:
{
"id": "qwen3.5-plus",
"name": "Qwen3.5 Plus (百炼)",
"reasoning": false,
"input": ["text"], // ❌ 只支持文本!
"contextWindow": 1000000,
"maxTokens": 65536
}
问题分析:
"input": ["text"]表示模型只接受文本输入- 虽然图片被下载到本地,但 OpenClaw 不会将图片传递给不支持图像的模型
- 模型接收到的只有文本占位符(如
![image]),所以回复"看不到图片"
✅ 解决方案
步骤 1:编辑配置文件
配置位置:~/.openclaw/openclaw.json 中的 models 数组
快速定位:
# 打开配置文件
vim ~/.openclaw/openclaw.json
# 搜索关键字(在 vim 中按 / 然后输入)
/input
# 或者搜索模型名称
qwen3.5-plus
配置说明:
- 这是 OpenClaw 的模型能力声明配置
- 告诉系统该模型支持哪些输入类型(text/image/file)
- 不是模型本身的参数,而是 OpenClaw 的适配层配置
打开 OpenClaw 配置文件:
vim ~/.openclaw/openclaw.json
步骤 2:修改模型配置
找到你使用的多模态模型配置(如 qwen3.5-plus),将 "input" 从 ["text"] 改为 ["text", "image"]:
修改前:
{
"id": "qwen3.5-plus",
"name": "Qwen3.5 Plus (阿里)",
"reasoning": false,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 128000,
"maxTokens": 8192
}
修改后:
{
"id": "qwen3.5-plus",
"name": "Qwen3.5 Plus (阿里)",
"reasoning": false,
"input": ["text", "image"], // ✅ 添加 "image"
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 128000,
"maxTokens": 8192
}
步骤 3:修改所有使用的模型
如果你的配置中有多个模型(如阿里云和百炼平台都有 qwen3.5-plus),需要全部修改:
// 阿里百炼
{
"id": "qwen3.5-plus",
"name": "Qwen3.5 Plus (百炼)",
"reasoning": false,
"input": ["text", "image"], // ✅ 添加 "image"
"contextWindow": 1000000,
"maxTokens": 65536
}
步骤 4:验证配置
运行配置检查:
openclaw doctor
确保没有配置错误:
✓ Config valid
步骤 5:重启 Gateway
openclaw gateway restart
等待 3-5 秒让服务完全启动。
🧪 验证测试
测试 1:飞书群聊
- 在飞书群聊中发送一张图片
- @机器人 并说"分析这张图片"
- 预期结果:机器人能准确描述图片内容
成功日志:
feishu: post message contains 1 embedded image(s)
feishu: downloaded embedded image img_v3_..., saved to /Users/xxx/.openclaw/media/inbound/xxx.jpg
feishu[default]: dispatching to agent
feishu[default]: dispatch complete (queuedFinal=true, replies=1)
测试 2:飞书私聊
- 在飞书私聊中发送一张图片
- 说"分析这张图片"
- 预期结果:机器人能准确描述图片内容
测试 3:WebChat
- 打开 OpenClaw WebChat 界面
- 发送一张图片
- 预期结果:机器人能识别并分析图片
📊 支持的多模态模型
以下模型支持图像输入(配置 "input": ["text", "image"]):
| 模型 | 提供商 | 配置 ID | 支持 |
|---|---|---|---|
| Qwen3.5 Plus | 阿里云 | qwen3.5-plus |
✅ 支持 |
| Qwen3 Max | 阿里云 | qwen3-max-2026-01-23 |
✅ 支持 |
| GPT-4o | OpenAI | gpt-4o |
✅ 支持 |
| Claude 3.5 Sonnet | Anthropic | claude-3-5-sonnet |
✅ 支持 |
⚠️ 风险提示(重要!)
不要随意添加 "image" 配置!
✅ 支持多模态的模型(可以添加 "image"):
- Qwen3.5 Plus/Max(阿里云/百炼)
- GPT-4o/GPT-4V(OpenAI)
- Claude 3/3.5(Anthropic)
❌ 不支持的模型(即使配置了也无效):
- glm-4.7-flash(智谱)- 纯文本模型
- 其他未声明支持图像的模型
错误配置会导致:
- 模型调用失败
- 返回错误信息
- 浪费 Token
如果不确定:先查阅模型官方文档,确认支持图像输入后再配置。
⚠️ 常见问题
Q1:为什么私聊可以,群聊不行?
A:私聊和群聊使用相同的媒体处理逻辑。如果私聊可以但群聊不行,通常是模型配置问题,而不是代码问题。
Q2:图片已下载,但模型说看不到?
A:这是典型的配置问题。图片下载和模型调用是两个独立的步骤:
- 下载:OpenClaw 下载图片到本地(已实现)
- 传递:根据模型配置决定是否传递给模型(需要
"input": ["image"])
Q3:配置后仍然无法识别图片?
A:检查以下几点:
- 配置是否生效:运行
openclaw doctor检查配置 - Gateway 是否重启:修改配置后必须重启 Gateway
- 日志是否有错误:查看
/tmp/openclaw/openclaw-*.log - 模型是否支持:确认使用的模型确实支持多模态
🔧 故障排查
查看图片下载日志
tail -f /tmp/openclaw/openclaw-$(date +%Y-%m-%d).log | grep -E "image|downloaded|embedded"
正常输出:
feishu: post message contains 1 embedded image(s)
feishu: downloaded embedded image img_v3_..., saved to /Users/xxx/.openclaw/media/inbound/xxx.jpg
查看媒体文件
ls -lh ~/.openclaw/media/inbound/
应该能看到下载的图片文件(.jpg, .png 等)。
查看模型调用日志
tail -100 /tmp/openclaw/openclaw-$(date +%Y-%m-%d).log | grep -E "dispatching|dispatch complete"
📝 总结
核心步骤
- 编辑配置:
~/.openclaw/openclaw.json - 添加
"image":模型配置的"input"数组 - 验证配置:
openclaw doctor - 重启服务:
openclaw gateway restart - 测试验证:在群聊/私聊/WebChat 中发送图片
配置示例
{
"id": "qwen3.5-plus",
"name": "Qwen3.5 Plus (百炼)",
"reasoning": false,
"input": ["text", "image"], // ✅ 关键配置
"contextWindow": 1000000,
"maxTokens": 65536
}
注意事项
- ⚠️ 修改配置后必须重启 Gateway
- ⚠️ 确保使用的模型确实支持多模态
- ⚠️ 图片大小有限制(默认 30MB)
- ⚠️ WebChat 需要额外配置 CORS 和文件上传支持
注:本文档基于 OpenClaw 2026.3.2 版本编写。不同版本的配置可能略有差异,请根据实际情况调整。