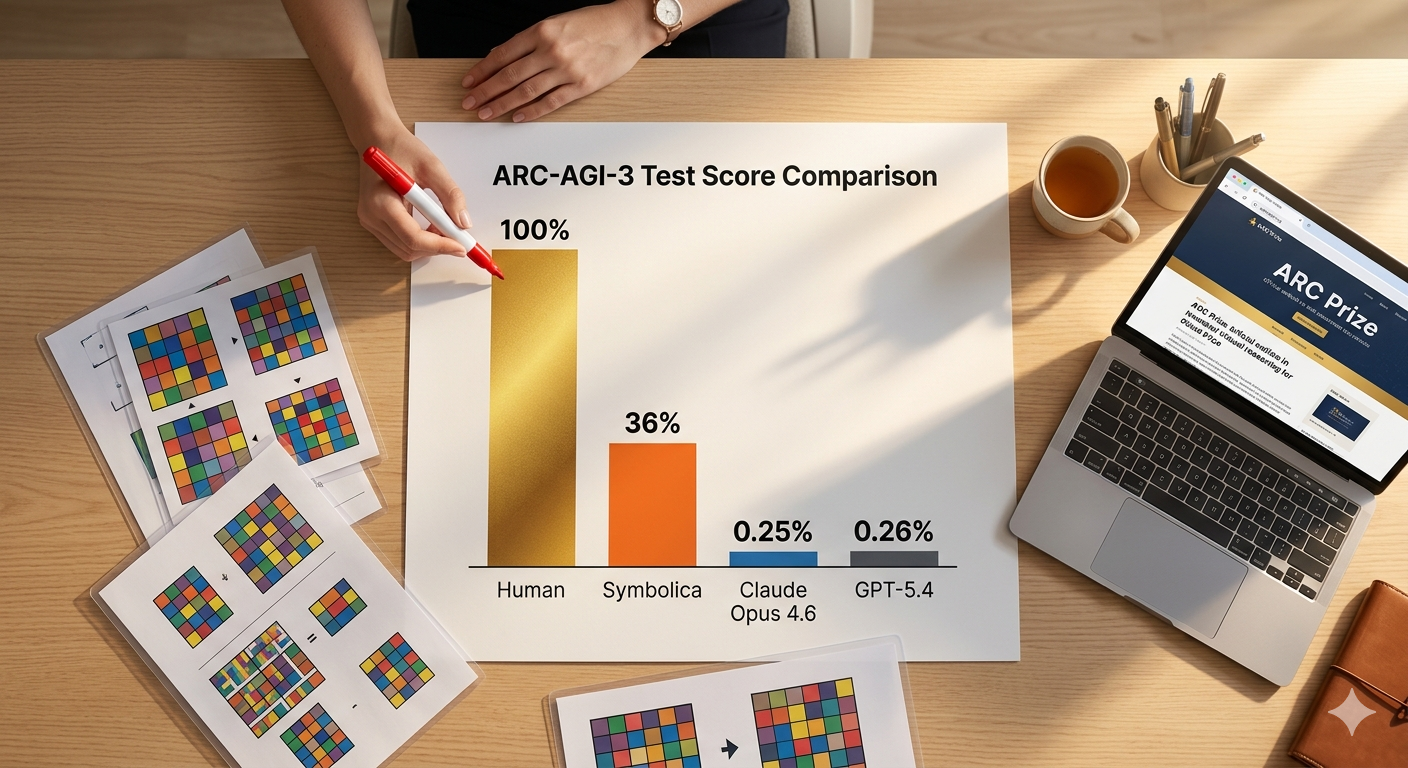
人类轻松 100 分,Claude Opus 4.6 只有 0.2 分。一家名不见经传的小公司,凭什么拿到 36 分?
2026 年 3 月 25 日,AI 圈迎来了一颗重磅炸弹。
ARC-AGI-3 测试成绩公布:人类玩家轻松完成 100% 任务,Claude Opus 4.6 得分 0.2%,GPT 5.4 得分 0.3%。而一家叫 Symbolica 的小公司,凭借 Agentica SDK 框架,一举拿下 36%。
180 倍的差距。
这不是简单的分数差距,而是暴露了当前 AI 最深层的问题——我们引以为傲的大语言模型,在真正的智能面前,可能只是个"高级复读机"。
一、ARC-AGI-3 到底在考什么?
先搞清楚这个"全球最难 AI 考试"是什么。
ARC-AGI(抽象与推理语料库)的核心理念就八个字:人类容易,AI 困难。
前两个版本(ARC-AGI-1 和 2)考的是静态谜题:给你几个输入输出示例,比如网格图案变换,让 AI 推断规律并应用到新输入。每个任务只给 2-6 个示例,没有训练数据可以背。
ARC-AGI-3 彻底变了。
它把测试从"做卷子"变成了"玩游戏"。AI 被丢进一个完全陌生的交互式环境,没有说明书,没有提示词,必须自己:
- 探索 —— 这个环境有什么规则?
- 推断 —— 我的目标是什么?
- 建模 —— 环境的内部机制是什么?
- 学习 —— 行动中实时调整策略
简单说,就是像人类一样现场学习、现场适应。
举个例子:你走进一个从没玩过的密室逃脱,没有攻略,只能靠观察、试错、归纳来逃出去。这就是 ARC-AGI-3 的测试场景。
而传统大模型的训练逻辑是:背下几十万道类似的密室题目,考试时靠模式匹配找最接近的答案。
一个是现场开卷,一个是背题库。高下立判。
二、为什么 Opus 4.6 只拿了 0.2%?
Claude Opus 4.6 是什么水平?
Anthropic 的旗舰模型,编程能力顶尖,推理能力顶尖,代理任务能力顶尖。在几乎所有公开 benchmark 上都是第一梯队。
但在 ARC-AGI-3 面前,它是个"学霸型学渣"。
问题出在哪?五个字:没有训练数据。
大语言模型的本质是什么?模式压缩 + 概率预测。GPT-4、Claude、Gemini,都是靠吃掉互联网上的万亿级文本,学习"下一个词该说什么"。
这种模式有两个致命弱点:
第一,无法真正抽象。
ARC-AGI-3 的每个任务都是全新的、唯一的。AI 必须从零开始理解规则,而不是从记忆库里找相似案例。
就像你问一个背了 10 年英语题库的学生:"用你从没见过的语法结构造句。"他当场傻眼。
第二,不会实时学习。
大模型是"预训练"的,权重固定。你问它问题,它基于训练时的知识回答。但在 ARC-AGI-3 里,环境每分每秒都在变,AI 必须边玩边学、边学边改。
这相当于要求一个已经毕业十年的医生,现场学会一种全新的手术技术,然后立刻上台主刀。
Opus 4.6 再强,也是"毕业十年的医生"。它没法现场学习。
三、Symbolica 的 36% 是怎么做到的?
既然大模型都不行,Symbolica 凭什么行?
先看这家公司的背景:
- 创始人 George Morgan,前特斯拉高级自动驾驶工程师
- 核心团队来自特斯拉、Neuralink、ClearML
- 顾问 Stephen Wolfram —— WolframAlpha 和 Mathematica 的创造者
这不是一支普通的创业团队,这是一群相信"符号推理"的叛逆者。
Symbolica 的技术路线,和大模型完全相反:
大模型:深度学习 + 海量数据 + 概率预测
Symbolica:范畴论 + 类型论 + 符号推理
简单说,大模型是靠"统计规律"猜答案,Symbolica 是靠"逻辑推导"算答案。
他们的 Agentica SDK 做了两件事:
第一,构建符号推理引擎。
不是让 AI 背模式,而是让 AI 建立形式化的逻辑表示。遇到新环境,先推理规则结构,再推导行动策略。
第二,实时学习与规划。
框架内置了探索-建模-规划-执行的闭环。AI 进入环境后,会主动试探、收集信息、更新内部模型、调整行动计划。
这才是真正的"智能体"——有目标、能探索、会学习、可调整。
36% 的分数意味着什么?意味着 Symbolica 的框架让 Claude Opus 4.6 的能力放大了 180 倍。
不是模型本身变强了,是用模型的方式对了。
四、这对 AI 发展意味着什么?
ARC-AGI-3 的成绩,给整个行业敲响了警钟。
过去两年,我们被大模型的"能力爆炸"冲昏了头脑。GPT-4 能写代码、Claude 能搞科研、Gemini 能做多模态……似乎 AGI 就在眼前。
但 ARC-AGI-3 告诉我们:现在的 AI,连"现场学一款新游戏"都做不到。
真正的智能是什么?
- 不是背下全人类的文字,然后模仿输出
- 是进入陌生环境,快速理解规则,高效达成目标
- 是像孩子一样,用极少样本就能学会新东西
- 是像人类一样,边做边学、边错边改
这些能力,大模型本质上是缺失的。
Symbolica 的崛起,说明了一条被忽视的路径:符号推理 + 神经网络的混合架构。
这不是要否定深度学习,而是说——纯深度学习可能不是通往 AGI 的唯一道路,甚至可能不是最优道路。
五、给开发者的启示
如果你正在用 AI 做开发,ARC-AGI-3 的成绩有几点启示:
1. 别迷信模型参数
Opus 4.6 的参数规模、训练数据量,肯定远超 Symbolica 的框架。但框架设计对了,小团队也能碾压大厂。
2. 关注架构设计
未来的竞争,不是"谁有更多 GPU",而是"谁有更好的架构"。Agent 框架、推理引擎、学习机制,这些才是护城河。
3. 混合路线可能是答案
纯深度学习有瓶颈,纯符号 AI 也有局限。神经网络 + 符号推理的结合,可能是突破的方向。
结语
ARC-AGI-3 的测试结果,像一盆冷水浇在 AI 圈的头上。
但也正是这盆冷水,让我们看清了现实:
现在的 AI 很强大,但远非真正智能。
Symbolica 的 36%,不是终点,而是起点。它证明了另一条路的存在——一条不依赖海量数据、不依赖暴力训练、更接近人类认知方式的路。
AGI 还没有到来。但 Symbolica 告诉我们,它可能比我们想象的更近,也可能比我们想象的更不同。
参考来源:
- ARC Prize Foundation 官方技术报告
- Symbolica AI 官方博客
- VentureBeat 对 Symbolica 的专访
- ARC-AGI-3 技术白皮书





